引き続きPythonプログラミングイントロダクション(12章)をみていきます。 この章ではナップザック問題を題材に貪欲アルゴリズムについて説明がされていますが、貪欲アルゴリズムはハフマン符号という符号化にも利用されています。 そして、ハフマン符号はJPEGやZIPで利用されている符号化です。
JPEGやZIPのような馴染みのある要素技術として利用されているハフマン符号とは何か、貪欲アルゴリズムの使いどころはどこなのかをみていきます。

ハフマン符号
ある文章の情報を表現するときにそれぞれの文字に2進数を割り当てたとしたとします。 文章中によく出る文字には短い2進数の割り当てを行い、あまり出てこない文字には長い2進数の割り当てを行うと、全体として短い2進数で文章を表現できるかもしれません。 これがハフマン符号です。
簡単な例として、a,b,c,d,eの文字が文章内に出てくる頻度を表にしました。
頻度の一番多い b には短い2進数 11 が割り当てられ、頻度の一番少ない a には長い2進数 000 が割り当てられています。
| 文字 | 頻度 | 割り当て |
|---|---|---|
| a | 5 | 000 |
| b | 35 | 11 |
| c | 25 | 01 |
| d | 15 | 001 |
| e | 30 | 10 |
Pythonによる実装
この割り当てを求めるためのPythonによる実装は下記になります。
| |
Nodeクラスは頻度と文字を管理するクラスです。文字はそのノード配下にある全ての文字を管理できるようにリストで配下の文字を管理しています。 まず出現頻度が一番低い文字と二番目に低い文字を探し出します。この時、前回も利用した優先度付きキューを利用して出現頻度が低い順にpopしています。 最終的に割り当てられる二進数文字はディクショナリで管理しています。一番目に出現頻度が低い文字には'0’を、二番目に頻度が少ないノードには'1’を追加していきます。
この2つのノードについて頻度を足し合わせた数を求め、ノードも結合した物を再度優先度付きキューに格納します。 改めてこの優先度付きキューについて出現頻度が低いものから順に同様の処理を行います。このように、頻度が低いノードをひたすら処理していくことで、割り当て文字を求めていきます。
実行結果は下記のようになります。
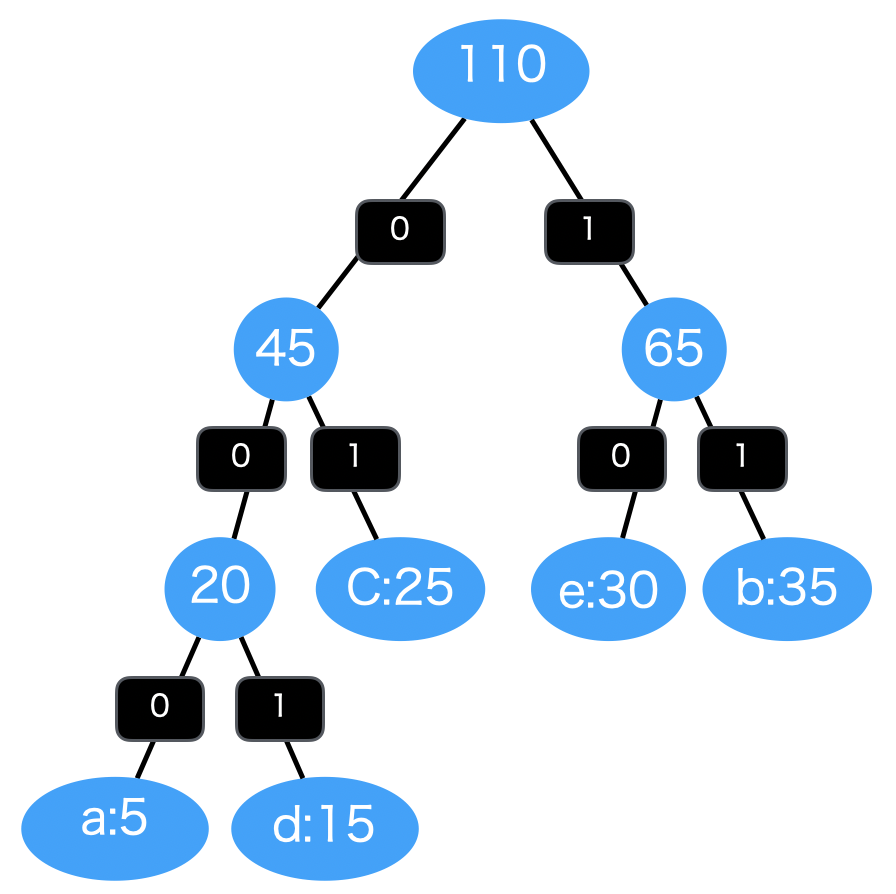
: {'a': '000', 'd': '001', 'c': '01', 'e': '10', 'b': '11'}
図で表すと下記のようになります。最初に a , d が処理され、 0, 1 が割り振られます。2つの出現頻度を足し合わせた 20 と二つのノードを結合させたものを優先度付きキューに再度格納します。
続いてこの 20 の出現頻度のノード ( a と d が結合したもの ) と c について処理を行います。 a , d には 0 が追加で割り振られ、 c には 1 が割り振られます。あとは同様に頻度を足し合わせ、ノードを結合していきながら繰り返し処理を行なっています。
まとめ
貪欲アルゴリズムを題材にハフマン符号について取り上げました。 そこまで複雑ではないアルゴリズムが、普段利用しているファイル形式の内部で利用されているということでテンションの上がる内容でした。