1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| class Node(object):
def __init__(self, name):
self.name = name
def getName(self):
return self.name
def __str__(self):
return self.name
def __lt__(self, i):
return None
class WeightedEdge(object):
"""重み付きの枝を表すクラス"""
def __init__(self, src, dest, weight):
self.src = src
self.dest = dest
self.weight = weight
def getSource(self):
return self.src
def getDestination(self):
return self.dest
def getWeight(self):
return self.weight
def __str__(self):
return self.src.getName() + '->(' + str(self.weight) + ')' + self.dest.getName()
class Digraph(object):
"""有向グラフを表すクラス"""
def __init__(self):
self.nodes = []
self.edges = {}
def addNode(self, node):
if node in self.nodes:
raise ValueError('Duplicate node')
else:
self.nodes.append(node)
self.edges[node] = []
def addEdge(self, edge):
src = edge.getSource()
dest = edge.getDestination()
weight = edge.getWeight()
if not (src in self.nodes and dest in self.nodes):
raise ValueError('Node not a graph')
self.edges[src].append((weight, dest))
def childrenOf(self, node):
return self.edges[node]
def __str__(self):
result = ''
for src in self.nodes:
for dest in self.edges[src]:
result = result + src.getName() + '->' + dest.getName() + '\n'
return result[:-1]
def printPath(path):
"""パスを表示するメソッド"""
result = ''
for i in range(len(path)):
result = result + str(path[i])
if i != len(path) - 1:
result = result + '->'
return result
def UCS(graph, start, end):
"""重み付き有向グラフを探索するメソッド"""
initPath = [start]
pathQueue = []
from heapq import heappush, heappop
heappush(pathQueue, (0, initPath))
while len(pathQueue) != 0:
(weight, tmpPath) = heappop(pathQueue)
print('Current UCS path:', printPath(tmpPath), ' weight:', weight)
lastNode = tmpPath[-1]
if lastNode == end:
return tmpPath
for (next_weight, nextNode) in graph.childrenOf(lastNode):
if nextNode not in tmpPath:
newPath = tmpPath + [nextNode]
heappush(pathQueue, (weight + next_weight, newPath))
def BFS(graph, start, end):
"""幅優先探索を行うメソッド"""
initPath = [start]
pathQueue = [initPath]
while len(pathQueue) != 0:
tmpPath = pathQueue.pop(0)
print('Current BFS path:', printPath(tmpPath))
lastNode = tmpPath[-1]
if lastNode == end:
return tmpPath
for (weight, nextNode) in graph.childrenOf(lastNode):
if nextNode not in tmpPath:
newPath = tmpPath + [nextNode]
pathQueue.append(newPath)
def testSP():
"""テストメソッド"""
nodes = []
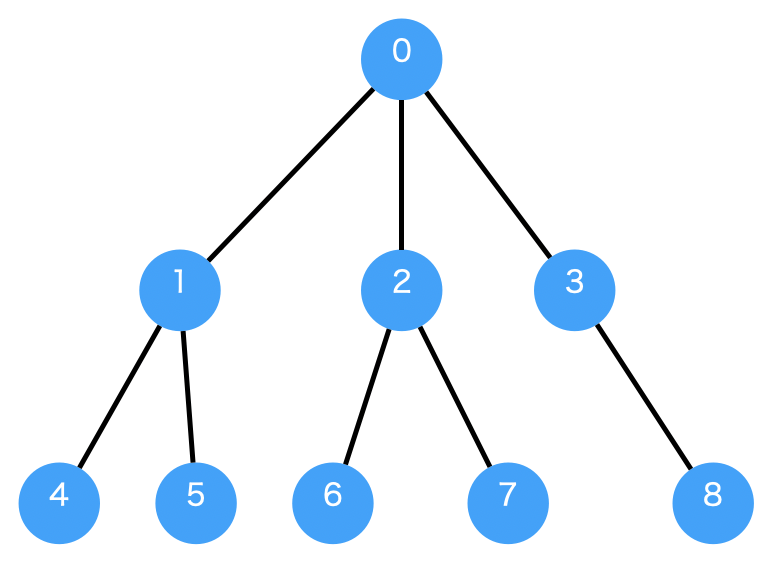
for name in range(9):
nodes.append(Node(str(name)))
g = Digraph()
for n in nodes:
g.addNode(n)
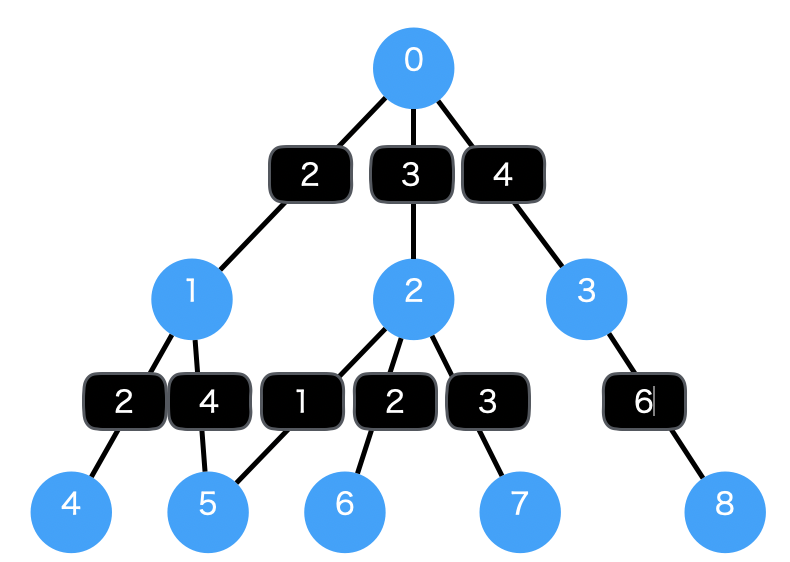
g.addEdge(WeightedEdge(nodes[0], nodes[1], 2))
g.addEdge(WeightedEdge(nodes[0], nodes[2], 3))
g.addEdge(WeightedEdge(nodes[0], nodes[3], 4))
g.addEdge(WeightedEdge(nodes[1], nodes[4], 2))
g.addEdge(WeightedEdge(nodes[1], nodes[5], 4))
g.addEdge(WeightedEdge(nodes[2], nodes[5], 1))
g.addEdge(WeightedEdge(nodes[2], nodes[6], 2))
g.addEdge(WeightedEdge(nodes[2], nodes[7], 3))
g.addEdge(WeightedEdge(nodes[3], nodes[8], 6))
sp = BFS(g, nodes[0], nodes[5])
print('Shortest path found by BFS:', printPath(sp), '\n')
sp = UCS(g, nodes[0], nodes[5])
print('Shortest path found by UCS:', printPath(sp))
testSP()
|