2年間履修した帝京大学の科目履修生コースを終えました。今年も引き続き科目履修生として登録するか、正科生への切り替えを検討していましたが、家庭の事情やら仕事の忙しさもあり、今年はこれまで学んできたことの復習を隙間時間に独学でやっていこうという事にしました。
一区切りということで2年間の科目履修生を振り返ってみたいと思います。
履修科目 2020年度履修科目 論理数学 数理統計学 離散数学 オートマトンと計算理論 コンピュータネットワーク データ構造とアルゴリズム 平日の仕事終わりや土日の多くの時間は授業を受けたりレポート書いたりしてました。仕事は比較的早めに上がれたのと、家族の協力あってのことでした。
おかげさまで全部単位は取れましたが、統計学が痛恨のC評価で、一番勉強した科目だったのですがセンスのなさが露呈しました。
年度の前半でほぼ試験も終わったので、詰め込めばもっと受けられたと思います。とはいえ1年に10〜15科目くらいが限界かなと思います。ちなみに暇だった年度の後半は勉強熱が高まっていたので、AWSの資格試験をバンバン受けてました。
2021年度履修科目 オペレーションズリサーチ コンピュータシミュレーション 2年目は2教科履修しました。2年目に教科数を減らしたのは仕事が忙しくなりそうと予想したからで、案の定忙しくなったので2教科にしておいてよかったです。この年も年度の前半でほぼ授業は終わりました。後半は仕事に追われてました。
授業の感想 レポートも細かいところまでしっかりみてもらえ、赤ペンでいっぱい書き込まれたフィードバックをもらった時は、間違えた気恥ずかしさはありつつもやってよかったなと思えました。
メールで何度か質問させてもらいましたが、こちらも丁寧に回答いただきました。
テストはコロナ禍と言うこともあり全てオンラインで受けました。なので本当にリアルでの大学生活は皆無でした。通信大学とはいえテストくらいは大学生気分を味わえると思っていたのですが、まぁ仕方がないですね。
お金に見合った価値があったかと言われると、自分の場合はあったと言い切れます。
ただ、大学は通えば良いというものではないことは、義務教育・高校・大学と進んだ若かりし頃を思えば想像ついていましたし、多くの方も実感としてあるのではないでしょうか。そこでどのように振る舞うかが重要です。単位はもちろん取れたら嬉しいですが、単位を取るためだけを目的にしていたら、あまり価値はないものになるでしょう。
仕事に好影響を与えるかと言われると微妙です。SREとして従事している今の仕事に直接影響はなかったかなと思います。そもそも自分の場合は仕事に生かすというよりかは、今従事しているコンピュータというお仕事の根幹をなす学問領域に興味があったというのが動機でした。
ただ、オンプレの経験がある人がパブリッククラウド上でのインフラ構築時に勘所に優れていたり、低レベルなプログラミング言語を操っていた人が高水準のプログラミング言語でも優れた能力を発揮されているケースを何度かみてきました。コンピュータサイエンスのような低レベルな知識が間接的にコンピュータに携わる上で好循環を与えるのかなとも考えています。
これから 冒頭にも書きましたが、今年は独学でコンピュータサイエンスを学んだりしながら授業で習ったことを今一度復習したいなと考えています。本当にたくさんの事を知らないんだなと痛感することができました。仕事やプライベートに余裕が出たら改めて門をたたきたいと思います。
Pythonプログラミングイントロダクション(20章) まで読みました。
20章はベイズ統計についです。
スパムフィルターでおなじみベイズフィルターですが、ベイズ統計を理解する上で重要な条件付き確率に関して問題が出ていました。
本書ではベイズ統計に関する例を取り上げつつ、Pythonで実装を提示してくれています。
そこは本書をみていただくとして、条件付き確率の問題について取り上げたいと思います。
条件付き確率 本書掲載の問題は下記になります。
あなたは森の中を歩き回り,美味しそうなキノコの群生を見つけた.
カゴいっぱいにキノコを採り,家に帰って旦那様のために,キノコ料理の準備を始める.
しかし,調理を始める前に,彼はあなたに,野生のキノコが毒キノコかどうかを本で調べるようにお願いした.
本によると,おしなべて野生キノコの80%は毒キノコとのことだ.
あなたは手元のキノコを本の中の写真と見比べ,95%の割合でそれが安心して食べられるキノコと判断した.
あなたはどの程度安心して,キノコ料理を旦那様に作ってあげられるだろうか.
採ってきたキノコが毒キノコの確率は80%になります。なので毒キノコで無い確率は20%です。これをP(B)とします。
写真をみて95%の確率で毒キノコで無いと判断していますが、実際採ってきたキノコが毒キノコの場合とそうで無い場合で、写真から判定される確率は異なると思います。
つまり写真と見比べて毒キノコで無いと判断した際の確率P(A)は毒キノコを採ってきたかそうで無いかという確率P(B)と独立でないと考えます。
仮に独立だとしても P(A) = P(A|B)です。
仮に、とってきたキノコが毒キノコで無いという条件のもと、写真と見比べた結果毒キノコで無い確率を95%とした場合、
採ってきたキノコが毒キノコでなく、写真で判断しても毒キノコで無い確率はいくらになるでしょうか。
写真判定シロ かつ 採ってきたキノコは毒でないを求めたいわけです。式で表すと
\(
P(写真判定シロ \cap 採ってきたキノコは毒でない) = P(採ってきたキノコは毒でない) \times P(写真判定シロ|採ってきたキノコは毒でない) \\\
\)
P(A)とかP(B)を使うと
P(A ∩ B) = P(B) × P(A|B)
つまり19%の確率で毒キノコではないということになります。
あなたは食べますか?
僕は食べません。
まとめ 条件付き確立の問題について取り上げてみました。
ここまでの章で学んできた頻度統計学とは一線を画するベイズ統計について興味を持たせてくれる章でした。
Pythonプログラミングイントロダクション(19章) まで読みました。
19章では統計的仮説検定についてです。
自転車競技の記録を伸ばす薬であるPED-XとPED-Yのどちらが優れているか無作為試験を行った結果から、得られた平均タイムについて検討していきます。
本当に平均タイムに有意な差があるのか、偶然発生した差なのかを検定をする方法が説明されています。
フィッシャーの統計的仮説検定 本書で述べられているフィッシャーの統計的仮説検定の手順は下記になります。この手順により観測結果が偶然起こったのか確率を評価していきます。
1. 帰無仮説(null hypothesis)と対立仮説(alternative hypothesis)を立てる.
2. 評価する標本についての統計的仮定を理解する.
3. 適切な検定統計量(test statistic)を計算する.
4. 帰無仮説における検定統計量の確率を得る.
5. その確率が、帰無仮説が偽であると推測できるほどに十分小さいかどうか,すなわち,帰無仮説を棄却(reject)するかどうかを決定する.
1. 帰無仮説(null hypothesis)と対立仮説(alternative hypothesis)を立てる. PED-XとPED-Yの平均値を例にとった場合、下記のようになります。
帰無仮説:PED-XとPED-Yの平均の差が0
対立仮説:PED-XとPED-Yの平均の差が0でない
2. 評価する標本についての統計的仮定を理解する. PED-XとPED-Y使用者のフィニッシュタイムは正規分布となり、標本は無限母集団から抽出した物でした。
3. 適切な検定統計量(test statistic)を計算する. t値を計算します。t値とは二つの平均の誤差が標準誤差で見て0からどれくらい差があるかを表した値です。
本書では-2.13165598142となりました。
標準誤差は17章で出てきたものです。
\(
\sigma_{a}^{2} : 母集団の分散 \\\
\sigma_{a} : 母集団の標準偏差 \\\
n : 標本サイズ
\)
\[ SE = \frac{\sigma}{\sqrt{n}} \]
4. 帰無仮説における検定統計量の確率を得る. p値を計算します。p値とは帰無仮説が成立する前提で、統計量が観測された値以上の極端な値が得られる確率のことです。
つまり、PED-XとPED-Yがの平均の差が0であったときに差が現れるような極端な値が得られる確率のことになります。
本書では0.0343720799815、つまり3.4%程になりました。
5. その確率が、帰無仮説が偽であると推測できるほどに十分小さいかどうか,すなわち,帰無仮説を棄却(reject)するかどうかを決定する. 本書ではp値が3.4%となり、PED-Xの方が優れていそうと言う結論になりかけますが、この後p値が信用ならないと言う話につながっていきます。
p値を何度も計算してみる 本書を読み進めていくと、この例はプログラムにより作り出されたデータであると言うたねあかしがされます。
平均値119.5、標準偏差5.0の分布と平均値120.0、標準偏差が4.0の分布からランダムにサンプリングした値が使われていました。
random.gauss関数でデータを作っています。
実際に何度か下記のようなプログラムを流してみると、p値の値は乱高下します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import random
from scipy import stats
def get_t_value ():
treatmenDist = (119.5 , 5.0 )
controlDist = (120 , 4.0 )
sampleSize = 1000
treatmentTimes, controlTimes = [], []
for s in range (sampleSize):
treatmentTimes. append(random. gauss(treatmenDist[0 ], treatmenDist[1 ]))
controlTimes. append(random. gauss(controlDist[0 ], controlDist[1 ]))
controleMeans = sum (controlTimes) / len (controlTimes)
treatMeans = sum (treatmentTimes) / len (treatmentTimes)
twoSampleTest = stats. ttest_ind(treatmentTimes, controlTimes, equal_var= False )
print ('Treatmeant mean - control mean = ' ,
treatMeans - controleMeans, ' minutes' )
print ('The t-statistic from two-sample test is ' , twoSampleTest[0 ])
print ('The p-value from two-sample test is ' , twoSampleTest[1 ])
for i in range (10 ):
twoSampleTest = get_t_value()
結果は下記のようになります。p値が1%台の時もあれば60%台の時もあります。
Treatmeant mean - control mean = -0.6843325129559474 minutes
The t-statistic from two-sample test is -1.0716961219246917
The p-value from two-sample test is 0.285226164284344
Treatmeant mean - control mean = -0.39645994742086543 minutes
The t-statistic from two-sample test is -0.6751950331252392
The p-value from two-sample test is 0.5004085432884583
Treatmeant mean - control mean = 0.25269386654427706 minutes
The t-statistic from two-sample test is 0.3950053957541872
The p-value from two-sample test is 0.6932658871131978
Treatmeant mean - control mean = 0.50100925426743 minutes
The t-statistic from two-sample test is 0.7660580410192988
The p-value from two-sample test is 0.4445624847162438
Treatmeant mean - control mean = -0.9383152222142996 minutes
The t-statistic from two-sample test is -1.3925614858916715
The p-value from two-sample test is 0.16555904568337207
Treatmeant mean - control mean = -0.4504161747373985 minutes
The t-statistic from two-sample test is -0.7134525526996994
The p-value from two-sample test is 0.4764536661236095
Treatmeant mean - control mean = -0.517887936147531 minutes
The t-statistic from two-sample test is -0.818800036206608
The p-value from two-sample test is 0.41390883875821693
Treatmeant mean - control mean = -0.7535810558372305 minutes
The t-statistic from two-sample test is -1.2462075073793941
The p-value from two-sample test is 0.21417712992121332
Treatmeant mean - control mean = -1.5033637291589912 minutes
The t-statistic from two-sample test is -2.347673847276862
The p-value from two-sample test is 0.019992408614120653
Treatmeant mean - control mean = -0.3150896341041829 minutes
The t-statistic from two-sample test is -0.5046312441817462
The p-value from two-sample test is 0.6144229896604907
と言うことで、200程度のサンプリング数だとp値がこれだけ上下することが示されました。
まとめ 仮説検定についての流れを追ってみました。取り上げた流れは2標本の両側検定と言うものです。
本書では他にも片側検定と1標本検定についての話題も取り扱っています。
本書ではp値が低いのは帰無仮説が実際に低いかもしれないし、母集団の代表的な例でない場合もあると言われています。
そして、このp値の問題を解決する考え方として20章のベイズ統計に続いていくわけです。
Pythonプログラミングイントロダクション(17章) まで読みました。
17章では中心極限定理について説明されています。
この章の目標の一つは「一つの標本から標本平均の信頼度を出す」ことにあります。
そのための道具として中心極限定理を利用します。
中心極限定理 中心極限定理についての引用は下記になります。
- 同じ母集団から抽出された標本サイズが十分に大きいと、標本の平均(標本平均)はおおよそ正規分布に従う
- この正規分布の平均は母集団の平均に非常に近い。
- 標本平均の分散は母集団の分散を標本サイズで割ったものに非常に近い
中心極限定理により標本平均は正規分布に従います。
また、標本平均の分散は母集団の分散を標本サイズで割ったものに非常に近いという事は、標本平均の標準偏差は母集団の標準偏差を標本サイズの平方根で割ったものに非常に近いということになります。
これを式にすると、標本平均の標準偏差を求める式は下記のようになります。
\(
\sigma_{a}^{2} : 母集団の分散 \\\
\sigma_{a} : 母集団の標準偏差 \\\
\sigma_{s}^{2} : 標本平均の分散 \\\
\sigma_{s} : 標本平均の標準偏差 \\\
n : 標本サイズ
\)
\[ \sigma_{s}^{2} = \frac{\sigma_{a}^{2}}{n} \]
\[ \sigma_{s} = \frac{\sigma_{a}}{\sqrt{n}} \]
母集団の標準偏差を標本サイズの平方根で割ったものは標準誤差とも言われます。
そしてこのとき必要な母集団の標準偏差は、ある一定数の標本サイズがあれば標本の標準偏差を用いて良いとされているそうです。
まとめると、下記の手順で中心極限定理が正しいかを見ていきます。
標本の値から標準偏差を求め、母集団の標準偏差とする。 標本平均の標準偏差を求める。 この標準偏差から95%信頼区間を導きます。 実際の母集団の平均値と標本平均の誤差を求める アニメのレーテイングデータで検証する kaggleのサイトでアニメのレーティングに関するデータ を利用させていただきました。
本書と同様の手順でこのデータから標本サイズ200のデータを元に信頼区間を導き、
実際の母集団から求めた平均との絶対誤差を元に信頼区間の値が妥当を見ていきます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import random
import pylab
import csv
def variance (X):
"""分散"""
mean = sum (X)/ len (X)
tot = 0.0
for x in X:
tot += (x - mean)** 2
return tot/ len (X)
def stdDev (X):
"""標準偏差(分散の平方根)"""
return variance(X)** 0.5
def read_anime_score (path):
"""データを読み込みスコアのリストを返す"""
scores = []
with open (path, newline= '' ) as f:
reader = csv. reader(f)
# skip header
next (reader)
for row in reader:
scores. append(float (row[15 ]))
return scores
data = read_anime_score('./anime_cleaned.csv' )
# 母平均
popMean = sum (data) / len (data)
# 標本サイズ
sampleSize = 200
numBad = 0
for t in range (10000 ):
sample = random. sample(data, sampleSize)
# 標本平均
sampleMean = sum (sample) / sampleSize
# 標準誤差
se = stdDev(sample) / sampleSize** 0.5
# 母平均と標本平均の誤差から信頼区間外のデータ数を求める
if abs (popMean - sampleMean) > 1.96 * se:
numBad += 1
print ('Fraction outside 95 % c onfidence interval =' , numBad / 10000 )
: Fraction outside 95% confidence interval = 0.05
概ね5%程度の結果が求められます。
中心極限定理で定義されている通り、標本サイズが十分大きいと標本平均が正規分布に従い、母集団の平均に非常に近いと言えそうです。
まとめ 本章は話の流れがわかりにくかったので最初は何を言っているのか正直わかりませんでしたが、
まとめてみると最終的に標本平均から信頼区間を求めたいのだとわかりました。
母集団の標準偏差が標本の標準偏差で代用できる点は気持ちの悪いところですが、本書でも下記のように説明されています。
多くの統計学者が言うには、母集団の分布がおおよそ正規分布であれば標本サイズが30から40で十分に大きい。
標本サイズが小さい場合にはt分布と呼ばれるものを使って区間計算したほうが良い。
t分布はこの後出てくるようなので一旦読み進めていくとします。
Pythonプログラミングイントロダクション(16章) まで読みました。
16章ではモンテカルロ・シミュレーションについての説明になります。
モンテカルロ・シミュレーションって大そうな名前がついていますが、この章までにやってきたランダムネスを利用したシミュレーションのことをモンテカルロ・シミュレーションといいます。
この章でもサイコロゲームを題材にランダムネスを利用したモンテカルロシミュレーションの実装がいくつか例示されています。
ランダムネスで円周率を求めるプログラミングなんかは痺れました。
ジャンケンのシミュレーション ここではジャンケンのモンテカルロ・シミュレーションをPythonで実装して理解を深めていきたいと思います。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
import pylab
import random
def janken ():
JANKEN_PATTERN = ['G' , 'C' , 'P' ]
while True :
a_t = random. choice(JANKEN_PATTERN)
b_t = random. choice(JANKEN_PATTERN)
if a_t != b_t:
break
return janken_judge(a_t, b_t)
def janken_kai ():
JANKEN_WIN_PATTERN = ['G' , 'G' , 'C' , 'P' ]
JANKEN_LOSE_PATTERN = ['G' , 'C' , 'C' , 'P' ]
while True :
a_t = random. choice(JANKEN_WIN_PATTERN)
b_t = random. choice(JANKEN_LOSE_PATTERN)
if a_t != b_t:
break
return janken_judge(a_t, b_t)
def janken_judge (a_t, b_t):
""" a_tとb_tは違う値の想定。
aが勝っていたらTrue, 負けていたらFalseを返す """
win_pattern = [('G' , 'C' ), ('C' , 'P' ), ('P' , 'G' )]
return (a_t, b_t) in win_pattern
def show_plot (trials, target):
a_rate = []
a_win = 0
for k in range (1 , trials + 1 ):
if target():
a_win += 1
a_rate. append(a_win / k * 100 )
pylab. plot(a_rate)
pylab. ylim(0 , 100 )
pylab. xlim(1 , trials)
pylab. xlabel('times' )
pylab. ylabel('rate' )
pylab. title('Junken' )
pylab. show()
def get_stdDev (trials):
a_rate = []
for i in range (0 , 100 ):
a_win = 0
for k in range (0 , trials):
if janken():
a_win += 1
a_rate. append(a_win / k * 100 )
return stdDev(a_rate)
def variance (X):
"""分散"""
mean = sum (X)/ len (X)
tot = 0.0
for x in X:
tot += (x - mean)** 2
return tot/ len (X)
def stdDev (X):
"""標準偏差(分散の平方根)"""
return variance(X)** 0.5
show_plot(1000 , janken)
show_plot(1000 , janken_kai)
print ('10 trials stdDev: ' , get_stdDev(10 ))
print ('100 trials stdDev: ' , get_stdDev(100 ))
print ('1000 trials stdDev: ' , get_stdDev(1000 ))
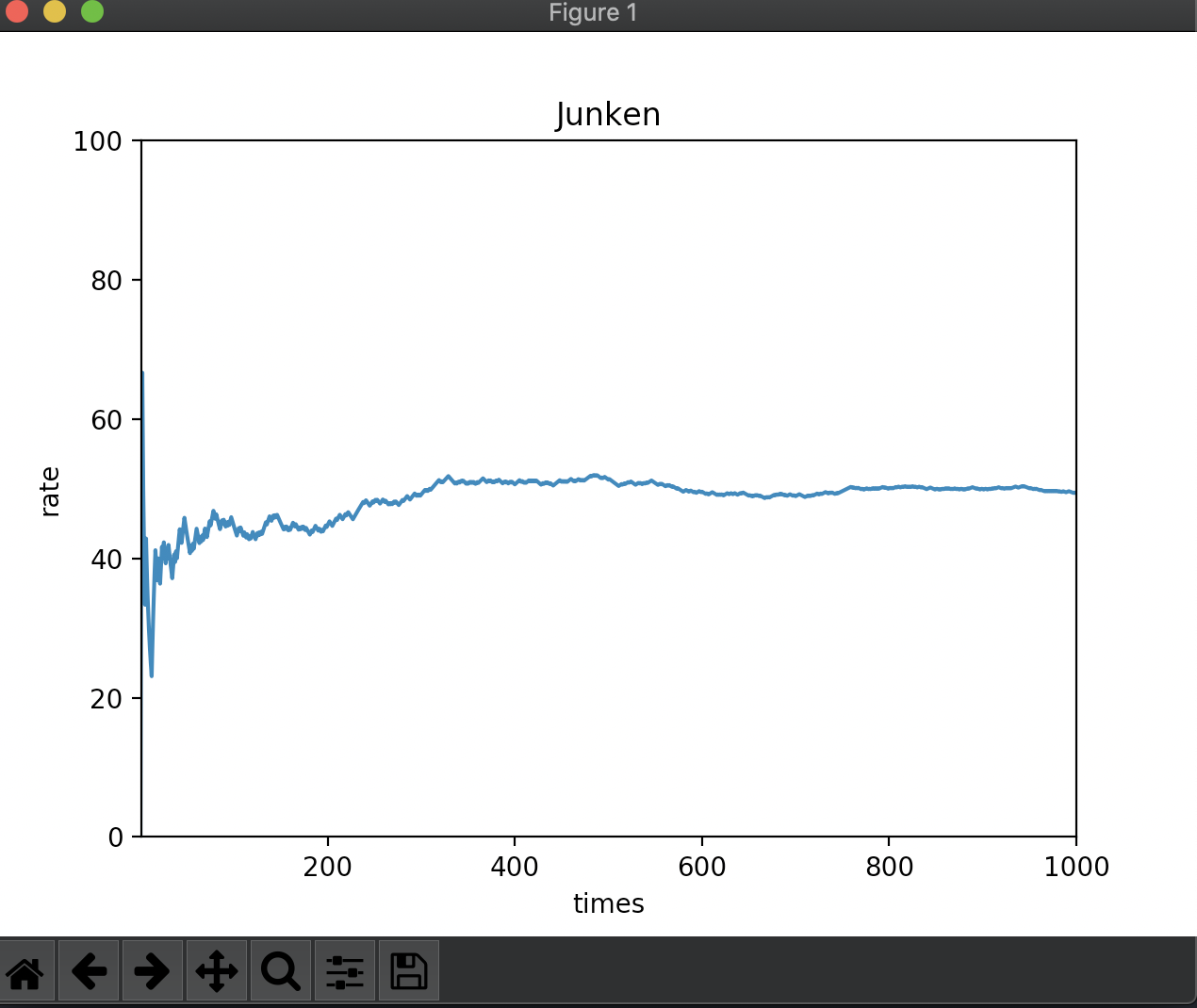
janken関数では、a,bそれぞれのグー(G)、チョキ(C)、パー(P)の中からランダムに選択した上で勝ち負けを判定しています。
あいこの場合はもう一度ランダムに選択しなおします。
完全にランダムにグー、チョキ、パーを選ぶ場合は試行回数が増えるについれて勝率は5割に近づいていきます。
15章で学んだ大数の法則の通りですね。
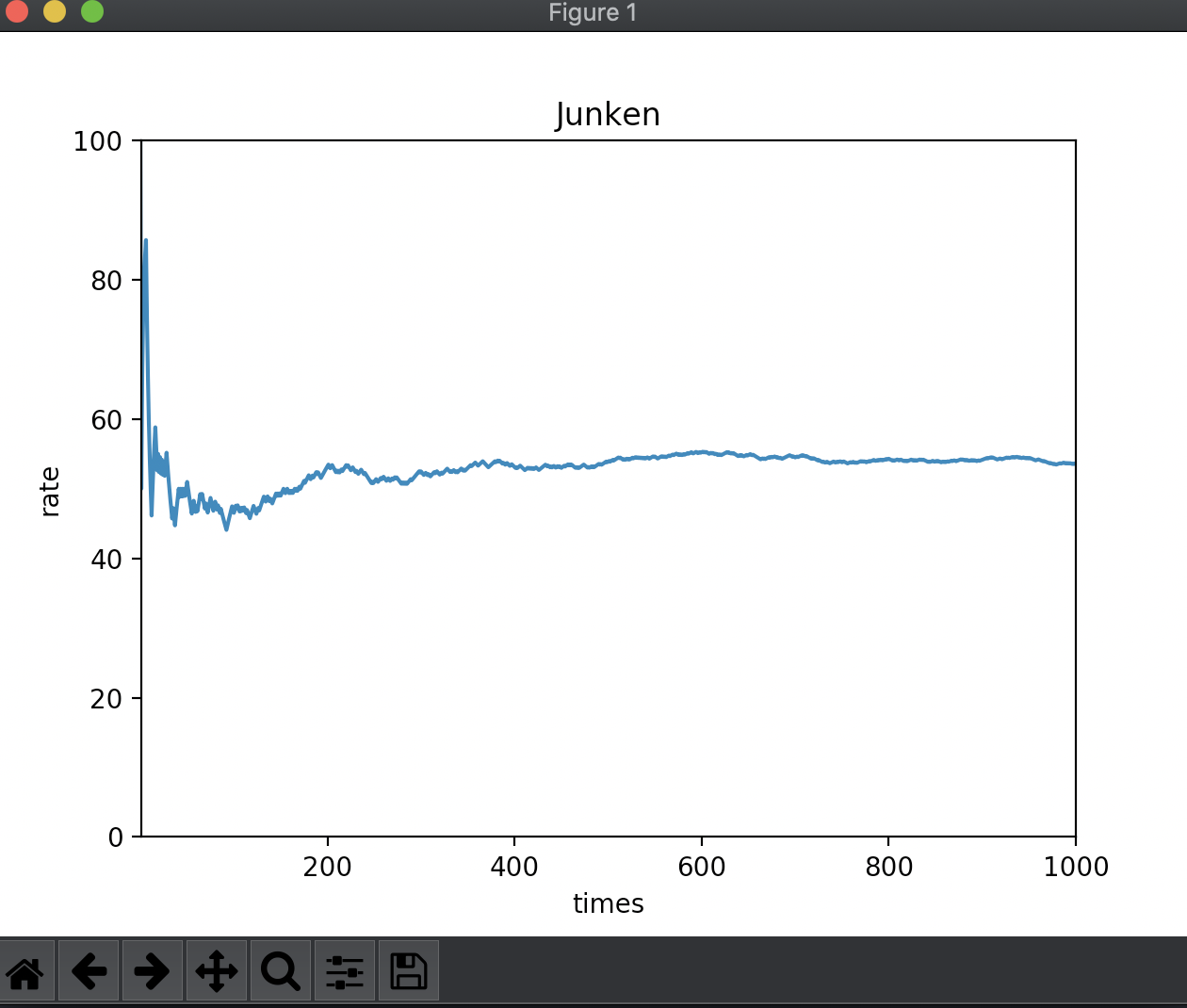
人間がジャンケンをする場合は完全にランダムとはいかず、グー、チョキ、パーのどれかに選択が偏ることがあるでしょう。
ランダムではありますが、aさんがグーを出しがち、bさんがチョキを出しがちな場合はaさんの勝率が上がっていきます。そんなjanken_kaiを作ってみました。
この場合はaさんの勝率が5割より上回っていますね。
続いて標準偏差を出してみました。
試行回数を増やすにつれ、標準偏差が減っていきます。
: 10 trials stdDev: 17.91612832955234
: 100 trials stdDev: 5.337158102067871
: 1000 trials stdDev: 1.6880153857382443
まとめ これまで学んだ統計の知識を織り交ぜつつ、ジャンケンを題材にモンテカルロ・シミュレーションをやってみました。
ここ何章かは思ったより統計学の内容が多いことに若干戸惑いもありましたが、内容も楽しいですしトレンド的にも良い題材なのかと思います。
Pythonを学ぶついでに統計学も学べるお得な一冊だと思います。
Pythonプログラミングイントロダクション(15章)まで読みました。
15章では確率統計を題材に、正規分布や関連する話題として信頼区間について述べられています。
様々な確率統計の題材について、Pythonでの実装とpylabを用いたグラフ表示付きで説明されているので、写経をしていくことで確率統計の知識が深まります。
その中でも確率分布についてみていこうと思います。
様々な確率分布 この章では様々な確率分布を例にPythonでの実装が例示されています。
この章で学ぶ確率分布の一部を列挙してみました。
名称 内容 一様分布 サイコロの目の出る確率のように全ての事象の起こる確率が等しい確率分布 2項分布 成功か失敗のように2つの値しか取らないような場合の確率分布 多項分布 2項分布と異なり、3つ以上の値を取るような場合の確率分布 指数分布 人体の薬物濃度のように指数関数的に濃度が減少していくような場合の確率分布
2項分布の練習問題 上記にあげた確率分布の中でも、2項分布については練習問題がついていたのでみていこうと思います。
練習問題は下記になります。
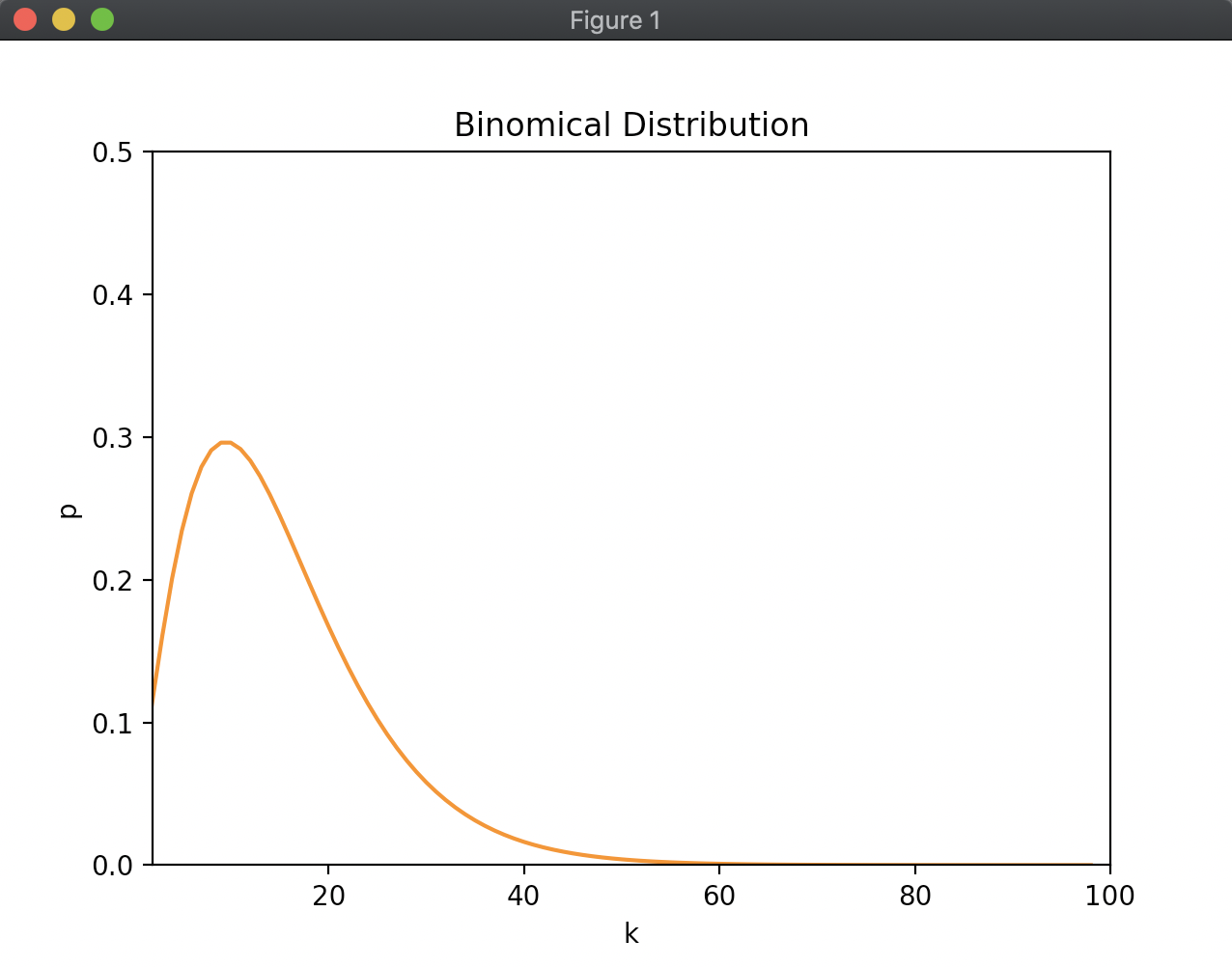
k回の公平なサイコロ投げでちょうど3が2回出る確率を計算する関数を実装せよ。
この関数を用いて、kを2から100まで変化させたときの確率をプロットせよ。
まず、サイコロを投げて3が出る確率は 1/6 になります。
k回サイコロを投げて2回しか3がでず、残りは3以外の数字が出るということになります。
k回サイコロを投げて3が2回出る組み合わせを考える必要があります。
k = 2 のときは
\[ \frac{1}{6} * \frac{1}{6} \]
k = 3 のときは、1,2回目が3の時、1,3回目が3の時、2,3回目が3の時の3通りの確率を足し合わせます。
\[ \frac{1}{6} * \frac{1}{6} * \frac{5}{6} + \frac{1}{6} * \frac{5}{6} * \frac{1}{6} + \frac{5}{6} * \frac{1}{6} * \frac{1}{6}\]
このような2項分布と呼ばれる確率分布の式は以下で表されます。
\[ {}_k \mathrm{ C }_t P^t(1 - P)^{k - t} = \frac { k! } { t!(k - t)! } P^t(1 - P)^{k - t} \]
Pythonでの実装は下記のようになります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import math
import pylab
def binomical_distribution (k, p, t):
c = math. factorial(k) / (math. factorial(t) * math. factorial(k - t))
return c * p** t * (1 - p)** (k - t)
def show_plot (p, t):
x, y = [], []
for k in range (t, 101 ):
x. append(k)
y. append(binomical_distribution(k, p, t))
pylab. plot(x)
pylab. plot(y)
pylab. ylim(0 , 0.5 )
pylab. xlim(2 , 100 )
pylab. xlabel('k' )
pylab. ylabel('p' )
pylab. title('Binomical Distribution' )
pylab. show()
show_plot(1 / 6 , 2 )
まとめ 2項分布の指練習について、実際にPythonで実装してみました。
この章で学んだ信頼区間についてはこの後でも深掘りされていくようなので楽しみです。
引き続きPythonプログラミングイントロダクション(12章)をみていきます。
この章ではナップザック問題を題材に貪欲アルゴリズムについて説明がされていますが、貪欲アルゴリズムはハフマン符号という符号化にも利用されています。
そして、ハフマン符号はJPEGやZIPで利用されている符号化です。
JPEGやZIPのような馴染みのある要素技術として利用されているハフマン符号とは何か、貪欲アルゴリズムの使いどころはどこなのかをみていきます。
ハフマン符号 ある文章の情報を表現するときにそれぞれの文字に2進数を割り当てたとしたとします。
文章中によく出る文字には短い2進数の割り当てを行い、あまり出てこない文字には長い2進数の割り当てを行うと、全体として短い2進数で文章を表現できるかもしれません。
これがハフマン符号です。
簡単な例として、a,b,c,d,eの文字が文章内に出てくる頻度を表にしました。
頻度の一番多い b には短い2進数 11 が割り当てられ、頻度の一番少ない a には長い2進数 000 が割り当てられています。
文字 頻度 割り当て a 5 000 b 35 11 c 25 01 d 15 001 e 30 10
Pythonによる実装 この割り当てを求めるためのPythonによる実装は下記になります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class Node ():
def __init__ (self , node, freq):
self . freq = freq
self . node_list = []
self . node_list. append(node)
def extend (self , node):
self . node_list. extend(node. node_list)
def __lt__ (self , other):
return self . freq < other. freq
def huffman (nodes):
from heapq import heappush, heappop
huffmanQueue = []
ans = {}
# 優先度つきキューにノードを格納する
for node in nodes:
heappush(huffmanQueue, (node. freq, node))
while len (huffmanQueue) > 1 :
(leftFreq, leftNode) = heappop(huffmanQueue)
(rightFreq, rightNode) = heappop(huffmanQueue)
# 一番頻度が少ないノードに'0'を追加
for s in leftNode. node_list:
ans[s] = '0' + ans. get(s, '' )
# 二番目に頻度が少ないノードに'1'を追加
for s in rightNode. node_list:
ans[s] = '1' + ans. get(s, '' )
totalFreq = leftFreq + rightFreq
leftNode. extend(rightNode)
heappush(huffmanQueue, (totalFreq, leftNode))
return ans
print (huffman([Node('a' , 5 ), Node('b' , 35 ), Node('c' , 25 ), Node('d' , 15 ), Node('e' , 30 )]))
Nodeクラスは頻度と文字を管理するクラスです。文字はそのノード配下にある全ての文字を管理できるようにリストで配下の文字を管理しています。
まず出現頻度が一番低い文字と二番目に低い文字を探し出します。この時、前回も利用した優先度付きキューを利用して出現頻度が低い順にpopしています。
最終的に割り当てられる二進数文字はディクショナリで管理しています。一番目に出現頻度が低い文字には'0’を、二番目に頻度が少ないノードには'1’を追加していきます。
この2つのノードについて頻度を足し合わせた数を求め、ノードも結合した物を再度優先度付きキューに格納します。
改めてこの優先度付きキューについて出現頻度が低いものから順に同様の処理を行います。このように、頻度が低いノードをひたすら処理していくことで、割り当て文字を求めていきます。
実行結果は下記のようになります。
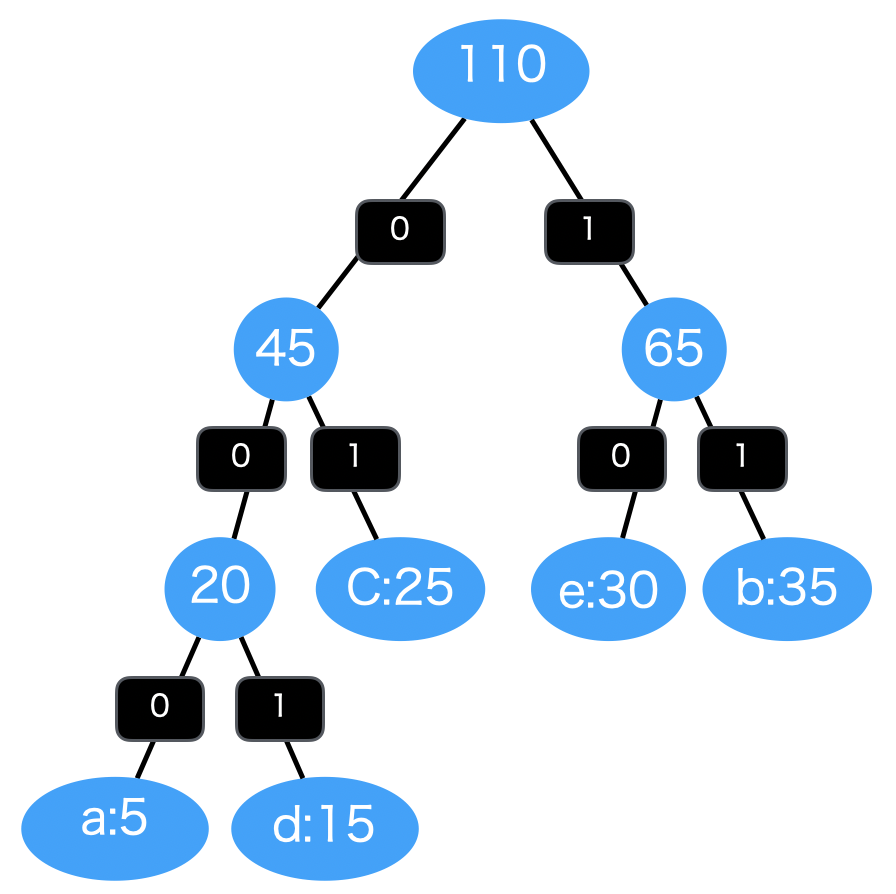
: {'a': '000', 'd': '001', 'c': '01', 'e': '10', 'b': '11'}
図で表すと下記のようになります。最初に a , d が処理され、 0, 1 が割り振られます。2つの出現頻度を足し合わせた 20 と二つのノードを結合させたものを優先度付きキューに再度格納します。
続いてこの 20 の出現頻度のノード ( a と d が結合したもの ) と c について処理を行います。 a , d には 0 が追加で割り振られ、 c には 1 が割り振られます。あとは同様に頻度を足し合わせ、ノードを結合していきながら繰り返し処理を行なっています。
まとめ 貪欲アルゴリズムを題材にハフマン符号について取り上げました。
そこまで複雑ではないアルゴリズムが、普段利用しているファイル形式の内部で利用されているということでテンションの上がる内容でした。
Pythonプログラミングイントロダクション12章まで読みました。
12章は最適化問題についてです。
空き巣が最適な盗みをはたらくためにはどのようなアルゴリズムで物を選んで盗んでいけば良いかを考えるナップザック問題や、
島をつなぐ橋を丁度一度ずつ渡るような散歩が可能か、オイラーによって定式化されたケーニヒスベルクの橋の問題などのグラフ最適化問題が題材になっています。
最短路問題としては深さ優先探索と幅優先探索が取り上げて、実装について丁寧に説明してくれています。
グラフ最適化問題の仕上げとして、章の最後に重み付き有向グラフの探索アルゴリズムについての練習問題があります。
この練習問題を元に重み付き有向グラフの探索問題を考えていきました。
探索アルゴリズム 練習問題をみていく前に、12章で紹介されている探索アルゴリズムについて軽くみていきます。
幅優先探索 (breadth first search: BFS) まずは探索をスタートするノードに接続する全ての子ノードを探索します。
探索対象がなければ、それぞれの子ノードについて、さらにその子ノードを探索していきます。
まずは同じレベルの子ノードを全て探索してから、次の深さの子ノードを探索していきます。
深さ優先探索 (depth-first search: DFS) 探索した子ノードにさらに子ノードがあった場合は、その子ノードを優先して探索していきます。
とにかく子ノードが見つかったら真っ先にそちらを探索していく形です。
重み付き有向グラフと幅優先探索 そして本章の最後には下記の問題が提示されています。
重み付き有向グラフを考えよう.
幅優先探索アルゴリズムによって最初に見つけられたパスは,
枝の重みの合計が最小であることを保証されているか?
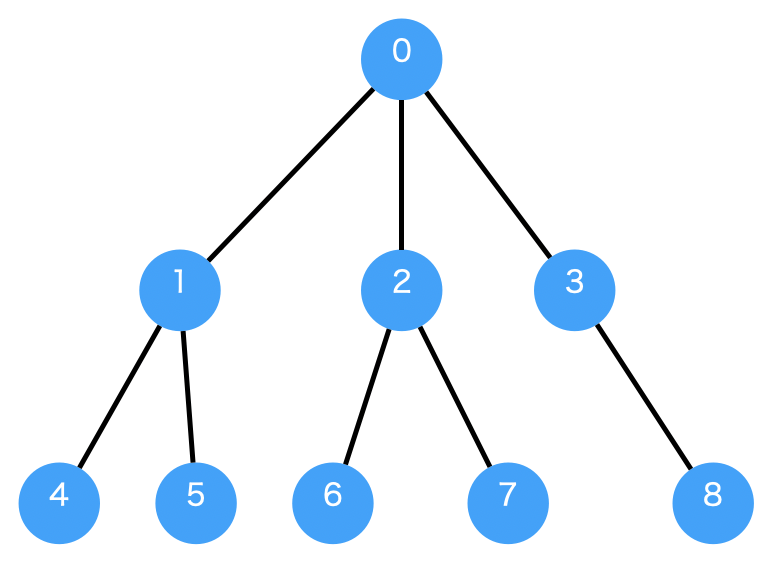
下記の図は重み付きの有向グラフの例です。ノードをつなぐ枝に重みが付いています。この重みを足した数字が幅優先探索で最小になるかというのが練習問題の問いになります。
この例で0からスタートして5を探索する幅優先探索を実施すると0 -> 1 -> 5 (重み6) が導き出されてしまいます。欲しい答えは 0 -> 2 -> 5 (重み4) ですから枝の重みが最小であることは保証されていませんね。
さて、どうすれば良いかというと、優先順位付きキューを用います。この場合、合計した重みが少ないパスを優先的に探索します。
下記は本書のプログラムを一部拝借しつつ、重みを扱えるようにしました。そして重みが一番少ないパスを探索するUCSメソッドを優先順位付きキューを用いて実装しています。
ちょっと長いですが全部載せておきます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
class Node (object ):
def __init__ (self , name):
self . name = name
def getName (self ):
return self . name
def __str__ (self ):
return self . name
def __lt__ (self , i):
return None
class WeightedEdge (object ):
"""重み付きの枝を表すクラス"""
def __init__ (self , src, dest, weight):
self . src = src
self . dest = dest
self . weight = weight
def getSource (self ):
return self . src
def getDestination (self ):
return self . dest
def getWeight (self ):
return self . weight
def __str__ (self ):
return self . src. getName() + '->(' + str (self . weight) + ')' + self . dest. getName()
class Digraph (object ):
"""有向グラフを表すクラス"""
def __init__ (self ):
self . nodes = []
self . edges = {}
def addNode (self , node):
if node in self . nodes:
raise ValueError ('Duplicate node' )
else :
self . nodes. append(node)
self . edges[node] = []
def addEdge (self , edge):
src = edge. getSource()
dest = edge. getDestination()
weight = edge. getWeight()
if not (src in self . nodes and dest in self . nodes):
raise ValueError ('Node not a graph' )
self . edges[src]. append((weight, dest))
def childrenOf (self , node):
return self . edges[node]
def __str__ (self ):
result = ''
for src in self . nodes:
for dest in self . edges[src]:
result = result + src. getName() + '->' + dest. getName() + ' \n '
return result[:- 1 ]
def printPath (path):
"""パスを表示するメソッド"""
result = ''
for i in range (len (path)):
result = result + str (path[i])
if i != len (path) - 1 :
result = result + '->'
return result
def UCS (graph, start, end):
"""重み付き有向グラフを探索するメソッド"""
initPath = [start]
pathQueue = []
from heapq import heappush, heappop
heappush(pathQueue, (0 , initPath))
while len (pathQueue) != 0 :
(weight, tmpPath) = heappop(pathQueue)
print ('Current UCS path:' , printPath(tmpPath), ' weight:' , weight)
lastNode = tmpPath[- 1 ]
if lastNode == end:
return tmpPath
for (next_weight, nextNode) in graph. childrenOf(lastNode):
if nextNode not in tmpPath:
newPath = tmpPath + [nextNode]
heappush(pathQueue, (weight + next_weight, newPath))
def BFS (graph, start, end):
"""幅優先探索を行うメソッド"""
initPath = [start]
pathQueue = [initPath]
while len (pathQueue) != 0 :
tmpPath = pathQueue. pop(0 )
print ('Current BFS path:' , printPath(tmpPath))
lastNode = tmpPath[- 1 ]
if lastNode == end:
return tmpPath
for (weight, nextNode) in graph. childrenOf(lastNode):
if nextNode not in tmpPath:
newPath = tmpPath + [nextNode]
pathQueue. append(newPath)
def testSP ():
"""テストメソッド"""
nodes = []
for name in range (9 ):
nodes. append(Node(str (name)))
g = Digraph()
for n in nodes:
g. addNode(n)
g. addEdge(WeightedEdge(nodes[0 ], nodes[1 ], 2 ))
g. addEdge(WeightedEdge(nodes[0 ], nodes[2 ], 3 ))
g. addEdge(WeightedEdge(nodes[0 ], nodes[3 ], 4 ))
g. addEdge(WeightedEdge(nodes[1 ], nodes[4 ], 2 ))
g. addEdge(WeightedEdge(nodes[1 ], nodes[5 ], 4 ))
g. addEdge(WeightedEdge(nodes[2 ], nodes[5 ], 1 ))
g. addEdge(WeightedEdge(nodes[2 ], nodes[6 ], 2 ))
g. addEdge(WeightedEdge(nodes[2 ], nodes[7 ], 3 ))
g. addEdge(WeightedEdge(nodes[3 ], nodes[8 ], 6 ))
sp = BFS(g, nodes[0 ], nodes[5 ])
print ('Shortest path found by BFS:' , printPath(sp), ' \n ' )
sp = UCS(g, nodes[0 ], nodes[5 ])
print ('Shortest path found by UCS:' , printPath(sp))
testSP()
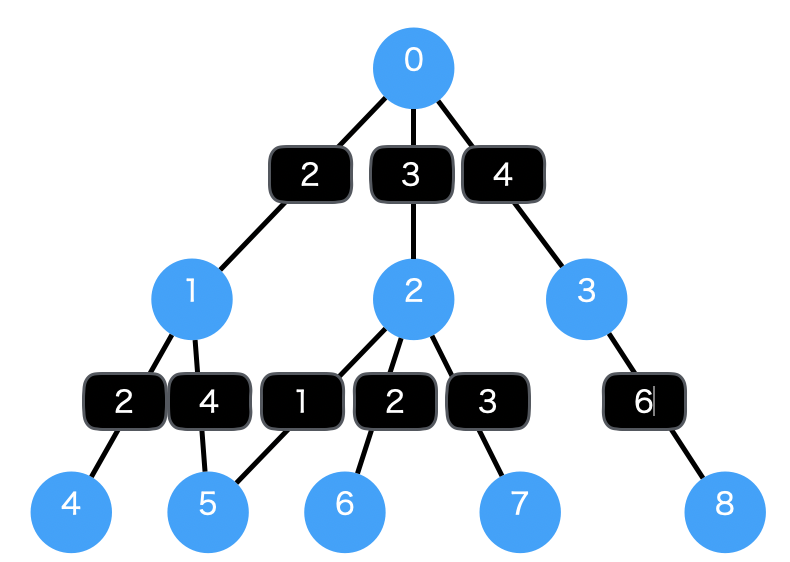
実行結果は下記のようになります。UCSメソッドでは重みを考慮しているため、最終的なパスは0->2->5になっています。
Current BFS path: 0
Current BFS path: 0->1
Current BFS path: 0->2
Current BFS path: 0->3
Current BFS path: 0->1->4
Current BFS path: 0->1->5
Shortest path found by BFS: 0->1->5
Current UCS path: 0 weight: 0
Current UCS path: 0->1 weight: 2
Current UCS path: 0->2 weight: 3
Current UCS path: 0->1->4 weight: 4
Current UCS path: 0->3 weight: 4
Current UCS path: 0->2->5 weight: 4
Shortest path found by UCS: 0->2->5
まとめ 12章では練習問題をみていきながら優先順位付きキューを用いた重み付き有向グラフの経路探索を実装してみました。
実装においてはWikipediaの均一コスト探索のページ や、 Pythonの公式ドキュメントにある優先順位付きキューの説明 を参考にさせていただきました。
Pythonプログラミングイントロダクション10章まで読みました。
9,10章は計算複雑性についてです。O(n)となる線形な計算量はイメージしやすいのですが、O(log n) のように対数が出てくるケースがどういうケースか最初イメージしずらかった覚えがあります。
この本では、9章で計算複雑性についての概念を、10章では二分探索やマージソートを例に、計算複雑性に対数が現れる様子を詳しく説明してくれています。
計算複雑性 9章で下記の計算複雑性について説明されています。
O(1) 定数計算時間 O(log n) 対数計算時間 O(n) 線形計算時間 O(n log n) 対数線形計算時間 O(n^k) 多項式計算時間 k:定数 O(c^n) 指数計算時間 c:定数
前述したように定数計算時間や線形計算時間はイメージしやすいです。定数計算時間なら入力によらず計算時間は一定となり、線形計算時間なら入力に比例して計算時間が増加します。
計算複雑性に対数が現れるケース 本書では O(log n): 対数計算時間や、O(n log n):線形対数計算時間となる場合を二分探索とマージソートを例に説明してくれています。
対数計算時間と二分探索 下記は二分探索のコード例です。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
def binary_search (lis, val):
u """ 引数で与えられたListの中から検索valの位置を検索して返す。
検索値が存在しない場合は-1を返す
"""
length = len (lis)
if length == 0 :
return - 1
return _search_array(lis, val, 0 , length - 1 )
def _search_array (lis, val, start, end):
mid = int ((start + end) / 2 )
if start == end and lis[mid] != val:
return - 1
if lis[mid] == val:
return mid
elif lis[mid] > val:
if (start == mid):
return - 1
return _search_array(lis, val, start, mid - 1 )
else :
return _search_array(lis, val, mid + 1 , end)
return - 1
print (binary_search([1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 ], 1 ))
print (binary_search([1 , 3 , 5 , 8 ], 4 ))
: 0
: -1
_search_binaryメソッドは与えられたリストを元に、検索する値が存在しない場合はリストの長さが1になるまで、リストの長さを半分にしながら再帰し続けます。
つまり、再帰回数をxとしたときに、
\[ 2^x = リストの長さ \]
\[ x = \log_{2} (リストの長さ) \]
\[ リストの長さを n とすると \]
\[ x = \log_{2} n \]
つまり計算複雑性は O(log n)となります。こうやって対数が計算複雑性に現れます。
線形対数計算時間とマージソート 下記はマージソートのコード例です。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
def merge_sort (lis):
return split_list(lis)
def split_list (arr):
"""
リストを半分に分ける
リストの要素が2つになったところで比較を行い、比較した結果をmerge_arrメソッドに渡す。
"""
if len (arr) <= 1 :
return arr
elif len (arr) == 2 :
if arr[0 ] > arr[1 ]:
return [arr[1 ], arr[0 ]]
else :
return arr
else :
br = int (len (arr) / 2 )
return merge_arr(split_list(arr[:br]), split_list(arr[br:]))
def merge_arr (arr1, arr2):
"""
ソート済みの渡されたリストを相互に比較しながらマージする。
"""
ret = list ()
len1 = len (arr1)
len2 = len (arr2)
i = j = 0
arr1_val = arr1[i]
arr2_val = arr2[j]
while len (ret) < len1 + len2:
if arr1_val < arr2_val:
ret. append(arr1_val)
if i < len1 - 1 :
i += 1
arr1_val = arr1[i]
else :
arr1_val = float ('inf' )
elif arr1_val >= arr2_val:
ret. append(arr2_val)
if j < len2 - 1 :
j += 1
arr2_val = arr2[j]
else :
arr2_val = float ('inf' )
return ret
print (merge_sort([]))
print (merge_sort([1 ]))
print (merge_sort([1 , 10 , 2 , 3 , 5 , 4 , 0 ]))
: []
: [1]
: [0, 1, 2, 3, 4, 5, 10]
split_listメソッドは与えられたリストの長さを元にすると、リストの長さが2以下になるまで再帰し続けます。これは二分探索と同じ計算時間になりますので、O(log n)になります。
merge_arrメソッドでは、while文でリストの長さ分ループしながら比較して要素の位置を更新していますので、計算時間は O(n)になります。
よって、これら二つを掛け合わせたものが計算時間になるので、O(n lon n)となります。
まとめ 9,10章から対数が現れる計算複雑性について取り上げました。対数が現れる計算複雑性のケースを有名なアルゴリズムとセットで学ぶことができました。
10章ではハッシュデータ構造についても言及があり、チェーン法のような実装が提示されていますが、15章で詳しく取り扱うとのこと。読み進める楽しみができました。
Pythonプログラミングイントロダクション8章まで読み終わりました。
6,7章はさらっと読み進められましたので飛ばして、今回は8章をみていきます。この章ではオブジェクト指向についての説明がされています。
継承、カプセル化、オーバーライド等のオブジェクト指向やクラスの定番の話題が説明がされている中で、リスコフの置換原則について軽く触れられていましたので詳しくみていきたいと思います。
リスコフの置換原則 本書ではリスコフの置換原則についてはさらっと説明されていますが、詳しく見ていきたいと思います。
下記はリスコフの置換原則に関する引用です。
サブクラスを用いてクラス階層を定義する時、
サブクラスはそのスーパークラスの振る舞いを拡張するように作るべきである.
もしスーパークラスのインスタンスを用いたコードが正しく動作するならば、
それはサブクラスのインスタンスに置き換えても正しく動作するように設計すべきである。
SuperHogeを継承したSubHogeのインスタンスがFugaServiceで利用されるケースを考えます。
FugaServiceのprocessメソッドではSuperHoge、SubHogeの両方のインスタンスを受け取れますが、どちらが渡ってきても動作します。
動作した結果が意図通りであれば問題ありません。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class FugaService :
def process (self , hoge):
hoge. echo()
class SuperHoge :
def echo (self ):
print ('super hoge' )
class SubHoge (SuperHoge):
def echo (self ):
print ('sub hoge' )
service = FugaService()
super_hoge = SuperHoge()
sub_hoge= SubHoge()
service. process(super_hoge)
service. process(sub_hoge)
: super hoge
: sub hoge
下記の例は意図通りではない継承のパターンです。
Employeeクラスを継承するEngineerクラスがあり、在職期間を管理しています。
親クラスのEmployeeクラスのperiodメソッドは’年’を引数にとることを前提としていますが、子クラスのEngineerクラスでは’月’を引数にとることを前提としています。
在職期間を元に有給付与とかしているプログラムがあったりるとバグってしまいますね。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Employee :
year = 0
month = 0
def period (self , year):
self . year = int (year)
self . month = int ((year - int (year)) * 12 )
class Engineer (Employee):
def period (self , month):
self . year = int (month / 12 )
self . month = int (month % 12 )
def print_exist (employee, year):
employee. period(year)
print ('在職期間は' , employee. year , '年' , employee. month , 'ヶ月です' )
employee = Employee()
engineer = Engineer()
print_exist(employee, 1.5 )
print_exist(engineer, 1.5 )
: 在職期間は 1 年 6 ヶ月です
: 在職期間は 0 年 1 ヶ月です
意図通りでないオーバーライドがある場合、インスタンスのタイプによって処理を分けるようなif文を書いたりする必要があります。上記の例だとEmpoyeeだと年を、Engineerだと月を引数に渡すような処理をif文で加えます。
上記の例の解決策もそうなのですが、そもそもメソッドのオーバーライドをやめさせたい場合もあるかと思います。常に親クラスのメソッドが呼ばれるようにしたい場合です。その場合は単に子クラスでのオーバーライドを止めれば良いです。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class FugaService :
def process (self , hoge):
hoge. echo()
class SuperHoge :
def echo (self ):
print ('super hoge' )
class SubHoge (SuperHoge):
pass
service = FugaService()
super_hoge = SuperHoge()
sub_hoge= SubHoge()
service. process(super_hoge)
service. process(sub_hoge)
: super hoge
: super hoge
オーバーライドをやめるのは簡単ですが、SuperHogeクラスを継承したサブクラスにそもそもオーバーライドさせないようにする方が便利です。
Python3.8以降であれば@finalを利用するのが一つの手です。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from typing import final
class FugaService :
def process (self , hoge):
hoge. echo()
class SuperHoge :
@final
def echo (self ) -> None :
print ('super hoge' )
class SubHoge (SuperHoge):
def echo (self ) -> None :
print ('sub hoge' )
service = FugaService()
super_hoge = SuperHoge()
sub_hoge= SubHoge()
service. process(super_hoge)
service. process(sub_hoge)
上記のファイルをhoge.pyとして保存して、mypyコマンドで型チェックをすると、下記のようなエラーになります。
1
2
3
❯ mypy hoge.py
hoge.py:15: error: Cannot override final attribute "echo" ( previously declared in base class "SuperHoge" )
Found 1 error in 1 file ( checked 1 source file)
型チェッカーはPythonランタイムとは別のものなので、開発環境に組み込んだりCIの一環として実装する必要があります。
まとめ 8章からリスコフの置換原則について取り上げました。何気に使っているオーバーライドですがリスコフの置換原則を守ることで、無駄なif文がない見通しの良いプログラムになります。